
¿Cuándo regresaremos a la normalidad? ¿Cuántos muertos habrá en México por la pandemia de Covid-19? Estas y otras preguntas las responden —supuestamente— los modelos matemáticos. El problema es que cada uno da resultados distintos. Según el oficial, habría sólo 6 mil muertos y el pico de contagios se ubicaría el 8 de mayo. Obviamente, eso no pasó. Otros pronostican más de 100 mil muertos. Pero los modelos no son oráculos sino herramientas de trabajo, y sólo funcionan si están hechos con rigor, transparencia y alejados de sesgos políticos.
6 de junio de 2020. En México y el mundo, las autoridades han citado los modelos de datos para prever el impacto de la pandemia como si se trataran de bolas de cristal. Pero, el oráculo también depende del lector que lo interpreta.
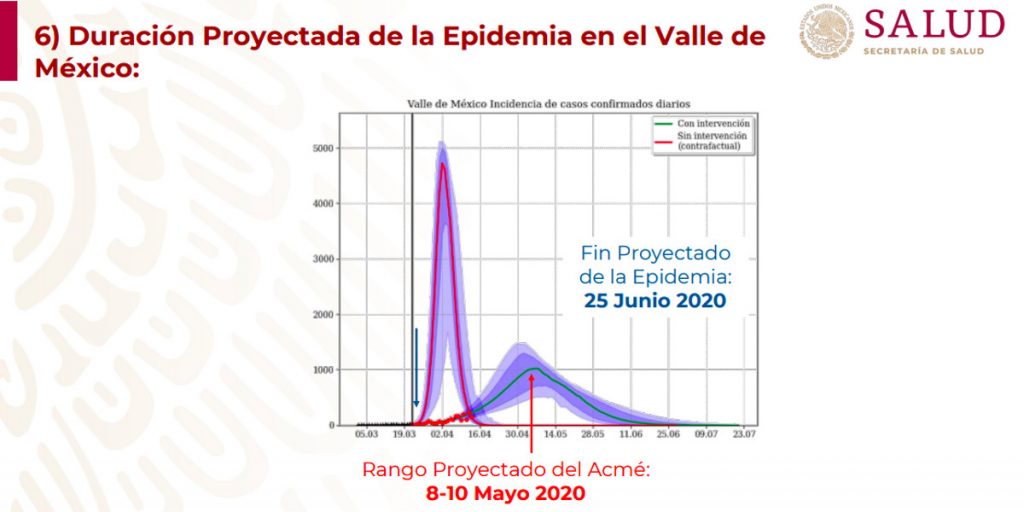
El primero de junio marcó el final de la Jornada Nacional de Sana Distancia, después de diez semanas de confinamiento domiciliario sugerido. La decisión se basó en un modelo de datos que ubicaba el pico de contagios hacia el 8 de mayo. Pero una pandemia es un fenómeno dinámico que no termina cuando lo señalan las estimaciones.
El 8 de mayo pasó y los números siguieron subiendo: infecciones, hospitalizados, fallecimientos. En la conferencia matutina de ese mismo día, el presidente Andrés Manuel López Obrador informó que el pico se extendería hasta el 20 de mayo: “… estamos en la fase de mayor contagio, según nos informaron puede durar hasta el 20 y a partir de ahí comience a bajar el número de contagios y ya el descenso de la pandemia”.
Otros modelos de datos estimaron escenarios diferentes. Uno hecho en el Instituto de Investigaciones en Matemáticas Aplicadas (IIMAS) de la UNAM (citado por Jorge Volpi en su columna del 16 de mayo en Reforma) alertaba que el pico máximo de contagios ocurriría en la primera semana de junio, es decir, justo ahora, cuando terminó la Jornada de Sana Distancia.
Otro, del Instituto de Física de la UNAM, publicado el 31 de mayo, prevé el punto mayor en la última semana de junio y atribuye el retraso de un mes respecto de la estimación oficial a un relajamiento en las medidas de mitigación alrededor de los festejos del Día de las Madres, el 10 de mayo.
Los modelos de datos no solo difieren en cuanto a fechas de máximos y mínimos contagios. También ofrecen escenarios muy distintos sobre las víctimas mortales de la pandemia. Hugo López-Gatell, subsecretario de Prevención y Promoción de la Salud y vocero oficial de la estrategia nacional contra el coronavirus, ha cambiado sus estimaciones con el paso de los meses.
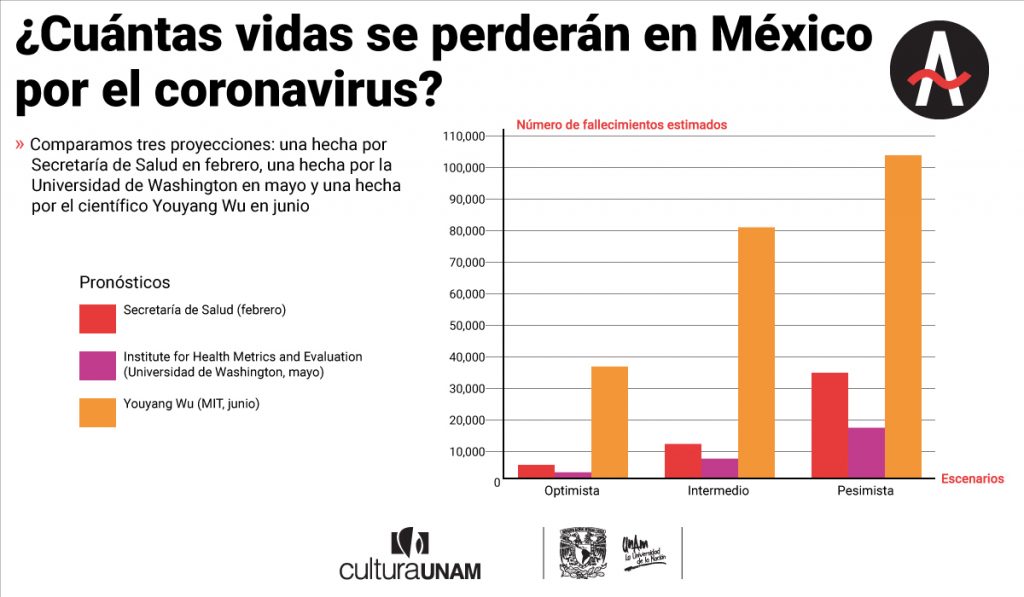
López-Gatell le dijo a El Universal el 3 de junio que proyecciones de la Secretaría de Salud (Ssa) hechas en febrero predecían un escenario intermedio de 12 mil 500 fallecimientos hasta el final de la primera oleada de la Covid-19. Su escenario optimista calculaba 6 mil víctimas fatales, cifra que comunicaron el 4 de mayo como estimado total. El miércoles 27 de mayo, en una comparecencia virtual ante la Junta de Coordinación Política del Senado, López-Gatell informó que podría haber hasta 30 mil fallecimientos. El jueves 4 de junio, actualizó esta cifra en una videoconferencia con la Junta de Coordinación Política de la Cámara de Diputados: “… preservamos de manera referencial esta idea de que podría en este primer ciclo médico llegar hasta 30 mil o incluso 35 mil defunciones, todas y cada una, lamentables”.
Los tres escenarios provienen de la proyección de febrero ya mencionada y que no corresponde a los modelos de medición utilizados en las fases 2 y 3 de la contingencia. López-Gatell señaló el viernes 29 de mayo que aquel primer modelo ya quedó muy limitado y fue sustituido por otros más sofisticados, que elaboraron científicos del Consejo Nacional de Ciencia y Tecnología (Conacyt).
Mientras tanto, un modelo internacional, hecho por el científico Youyang Gu, especialista en aprendizaje de máquinas del Instituto Tecnológico de Massachussets (MIT), y actualizado el 4 de junio, pronostica tres escenarios para el 1 de septiembre en México: uno optimista con 37 mil muertos, uno intermedio con 81 mil y uno grave con 104 mil.
Los intérpretes del oráculo
La pandemia del virus SARS-CoV-2 puso en la discusión pública un oficio que antes casi nadie conocía: los modeladores de datos. El análisis y procesamiento de datos es un trabajo colaborativo en el que convergen epidemiología, matemáticas, biología molecular, geoestadística, entre otras disciplinas. Estos equipos analizan decenas de variables para pronosticar escenarios sobre capacidad hospitalaria, aproximaciones de casos de contagio, e incluso proyecciones sobre cuántos fallecimientos puede alcanzar una región en cierto periodo.
“Los modelos de datos pueden ayudarnos a conocer distintos aspectos de la epidemia, como por ejemplo qué tan rápido se está dispersando el virus en distintas regiones del país”, explica el doctor Malaquías López Cervantes, miembro de la Comisión Universitaria para la Atención de la Emergencia por coronavirus de la UNAM. “Con eso puede decirse si hay diferencias importantes, si están en diferentes momentos de la epidemia y cuáles serían más adecuadas como medidas de contención o de mitigación”.
El gobierno federal cuenta con un grupo de asesores científicos provenientes de centros de investigaciones e instituciones académicas de renombre. Entre ellos se encuentran Centros Públicos de Investigación de Conacyt, como el Centro de Investigaciones en Matemáticas (Cimat) y el Centro de Investigación en Ciencias de Información Geoespacial (CentroGeo), así como la Coordinación de Repositorios, Información y Prospectiva (CRIP) del mismo consejo; también colaboran investigadores del Instituto de Matemáticas (IM) de la UNAM.
No existe un registro público claro sobre los equipos que asesoran a las autoridades estatales. Aquellos que se conocen han sido mencionados por los gobiernos locales en sus redes sociales o en entrevistas con medios de comunicación. Los modelos de datos y proyecciones de la Secretaría de Salud de la CDMX vienen de un grupo coordinado por la Secretaría de Educación, Ciencia, Tecnología e Innovación (Sectei), en colaboración con la Comisión Coordinadora de los Institutos Nacionales de Salud, así como científicos del Centro de Investigación y de Estudios Avanzados del IPN (Cinvestav) y de la UNAM.
Por su parte, el gobierno de Jalisco es asesorado por investigadores del Comité Universitario de Análisis sobre Salud Pública de la Universidad de Guadalajara. Mientras que la Secretaría de Salud de Nuevo León ha señalado que entre sus asesores estuvieron, además de científicos locales, miembros del Servicio de Inteligencia Epidemiológica de la provincia coreana de Gyeonggi, con quienes han sostenido sesiones a distancia.
Modelos de datos, nueva normalidad y semáforos rojos
Los modelos de datos epidemiológicos no son suficientes para pronosticar el fin de la pandemia o el regreso a la nueva normalidad. “Predecir las epidemias es inherentemente complicado, es como predecir el clima”, explica Octavio Miramontes, investigador del Instituto de Física de la UNAM. “No se puede predecir de aquí a dos meses. Basta con que las personas en una situación real no sigan los patrones solicitados para que cambien los parámetros”.
Un gobierno demanda precisión para decidir si reactiva la economía, el turismo, la actividad escolar. “En la política se quiere tener esas ‘certezas’ para anunciar medidas, pero en la simulación estadística hay un margen de error considerable”, dice Raúl Rojas, investigador mexicano y profesor de matemáticas e informática en la Universidad Libre de Berlín. “El modelador mismo debe ser el más crítico de sus propios resultados y resistirse al uso político de sus conclusiones”.
En una columna publicada el 9 de mayo en El Universal, Rojas cuestionó la precisión con la que el modelo de datos utilizado por la Secretaría de Salud anunciaba el final de la pandemia para el 25 de junio. También refrendó las críticas hechas por otros académicos al subregistro de casos de contagio y sugirió que el gobierno estaba utilizando estas proyecciones para justificar la reactivación económica a pesar de que la pandemia no se había contenido.
Rojas no es el único académico en señalar inconsistencias en las proyecciones epidemiológicas de la Secretaría de Salud. Ni la comunidad científica ni la ciudadanía en general conocen a profundidad los modelos matemáticos que determinaron el encierro. A pesar de tratarse de una producción científica generada con recursos públicos, los detalles matemáticos permanecieron ocultos durante semanas. Es imposible verificar la funcionalidad de un modelo si no puede estudiarse con detenimiento.

Conacyt: metodología opaca
Las proyecciones de la Secretaría de Salud sobre el desarrollo del coronavirus en México generaron dudas desde el inicio. Primero le tocó al Modelo Centinela, la guía principal para toma de decisiones en la Fase 2, que entró en funcionamiento el 23 de marzo de 2020. Este modelo se alimentaba de datos reportados por una muestra representativa de unidades de salud del Sistema Nacional de Vigilancia Epidemiológica. Es decir, de origen no trabajaba con el 100 por ciento de los datos disponibles. El uso de este método justificó la negativa de las autoridades de realizar pruebas de diagnóstico a gran escala.
El Modelo Centinela empezó a utilizarse en México en 2006, después de que fuera validado por la Organización Mundial de la Salud para monitorear el comportamiento de algunos virus. A partir de la epidemia de influenza A/H1N1, en 2009, Secretaría de Salud enfocó el Centinela en la vigilancia de la influenza estacional. Es un método que se usa para vigilancia de diversas enfermedades en Canadá y en otros países de América Latina, pero México fue el primero en utilizarlo para el coronavirus. Está diseñado para virus que ya han sido estudiados, pues detecta los cambios en sus patrones de comportamiento.
Esto resultó en un margen muy amplio de subregistro de casos que fue señalado por medios nacionales e internacionales. López-Gatell fue claro respecto al funcionamiento del Método Centinela: debido a la magnitud de la población mexicana (más de 126 millones de habitantes), este modelo daría datos más precisos y veloces en cuanto a infecciones. El mismo Centinela estimaba que los contagios eran casi ocho veces más que los casos confirmados oficialmente. Para calcular el número real de casos tendrían que multiplicarse los registrados por Centinela por un número de ajuste: ocho. En los primeros días de mayo, esto significaba que podría haber hasta cien mil casos de contagio adicionales a los 23 mil que tenían confirmados por pruebas diagnósticas en todo el país.
A principios de mayo dos medios internacionales (El País y The New York Times) publicaron reportajes en los que exhibieron una brecha considerable entre las cifras oficiales de contagios y fallecimientos y las producidas por estimaciones independientes. Por ejemplo, el 7 de mayo, cuando la Secretaría de Salud confirmaba 29 mil 616 casos de contagio (242 mil 851, con el ajuste), El País calculaba entre 620 mil y 730 mil contagios leves o asintomáticos en México.
Fase 3: en el ojo del huracán
Con la llegada de la Fase 3, el 21 de abril, el Modelo Centinela dejó de ser funcional. Ese día López-Gatell mencionó que se añadiría una nueva práctica a la medición de los casos. La aclaración de que el Centinela ya no era el modelo principal llegó hasta el 3 de mayo. El modelo C^3 (por las iniciales de los apellidos de sus creadores) quedó como primera referencia para la Fase 3; proyecta brotes regionales, analiza la dinámica de los servicios hospitalarios y cuantifica su propia incertidumbre. Sus autores son los matemáticos Marcos Capistrán y Andrés Christen, del Centro de Investigación en Matemáticas (Cimat), y Antonio Capella, del Instituto de Matemáticas de la UNAM (IM-UNAM). El equipo declinó nuestra solicitud de entrevista. Aunque cambió de nombre a AMA (otra combinación de las iniciales de sus creadores), este modelo de datos también fue blanco de críticas por su opacidad.

Otro método utilizado por la Ssa en la pandemia es el Modelo Gompertz. Fue elaborado por Graciela María de los Dolores, Rogelio Ramos Quiroga y Domingo Iván Rodríguez González, del Cimat. De acuerdo con Conacyt, esta curva “permite proyectar regiones en diferentes etapas de la pandemia”. Se trata de un ajuste simple utilizado para estimar el crecimiento lineal de los casos de contagio a nivel nacional y regional.
Ambos modelos de datos son la base para la toma de decisiones logísticas de vida o muerte, como cuántas camas y cuántos ventiladores se necesitarán para atender a los enfermos más graves en los próximos meses. Sin embargo, su metodología, conjunto de ecuaciones y parámetros permanecieron ocultos al público hasta mes y medio después de que se convirtiera en la fuente de análisis principal.
Una de las críticas al Modelo AMA está en la validez de los datos con los que se alimenta, pues tienen un desfase de hasta 15 días, dependiendo de la velocidad de registro de cada entidad. A mediados de abril, la Secretaría de Salud publicó su base de datos sobre la pandemia en formato abierto. Esto permitió a científicos independientes y académicos probar sus propios modelos de datos. Los ya mencionados (generados por el IIMAS y por el Instituto de Física de la UNAM) llegaron a conclusiones menos optimistas a partir de los mismos datos que el Modelo AMA.
La importancia de la nota metodológica
Ante estas discrepancias el 28 de mayo el Conacyt lanzó una plataforma para exhibir los resultados del grupo científico asesor. El Ecosistema Nacional Informático (ENI) COVID-19 parece ser un ejercicio de transparencia: esta es la ciencia que hacemos para ganar la batalla, parece decir. Sin embargo, la plataforma deja mucho que desear tanto para la lectura del público general (casi imposible sin conocimientos de estadística) como para la comunidad científica.
La presentación oficial de los modelos de datos AMA y Gompertz es meramente de visualización de resultados; carece de notas metodológicas, de definición de parámetros, de explicación de sus condiciones. “Ninguno de los dos está bien documentado, no hay información de qué están haciendo realmente”, dice Irving Morales, doctor en física y fundador de Morlan, una agencia independiente de análisis científico y visualización de datos. A fines de abril, el gobierno de la Ciudad de México publicó su propio modelo de datos. El esfuerzo de transparencia no fue perfecto (falta publicar sus condiciones iniciales y explicar cada cuándo ajustan sus parámetros), pero es más claro que el del gobierno federal. “En este caso no conocemos nada, solo el nombre”, apunta Morales. “Queda la duda de cómo están aplicando el modelo, qué variables, qué datos”.
María Elena Álvarez-Buylla, directora del Conacyt, presentó el ENI COVID-19 como una puerta abierta para consulta ciudadana y como una invitación de colaboración para la comunidad científica. “Es una llamada a todas y a todos los colegas que estén interesados en aportar de manera articulada y de manera incidente”, dijo en conferencia. Sin embargo, no mencionó canales de comunicación para que puedan acercarse a ella investigadores ajenos al grupo asesor, como Irving Morales y otros analistas o dateros independientes que desde el inicio de la pandemia publican sus proyecciones en línea. “Con lo que hay ahorita no es posible hacer una contribución. El modelo no es reproducible y eso limita una colaboración”, dice Morales, a la mañana siguiente de la conferencia. “Puedo intentarlo, destilar su página, ajustarlo y el canal que me queda es preguntar por Twitter”.
La invitación de Álvarez-Buylla para contribuir en la búsqueda de soluciones para el coronavirus llegó unos días después de que el consejo notificó a sus centros de investigación un recorte presupuestal operativo del 75%. Conacyt frenó esta medida el 2 de junio, después de las manifestaciones de rechazo de miembros y egresados de estos centros.
La metodología del modelo AMA finalmente se hizo pública la noche del 3 de junio de 2020, aunque no por la voluntad de las autoridades. Los autores del modelo lo mandaron a un archivo público como prepublicación de un paper académico.
Un tuit del matemático Rafael Villarroel, de la Universidad Autónoma del Estado de Hidalgo, alertó: “El preprint que esperábamos”. Villarroel vinculó a la prepublicación del artículo “Pronosticando demanda hospitalaria durante brotes epidémicos de Covid-19” en el repositorio virtual ArXiv, un archivo público y de distribución libre de artículos académicos administrado por la Universidad de Cornell, en Estados Unidos.
El artículo está firmado Capistrán, Capella y Christen y fue enviado por el primero para publicación el martes 2 de junio. Complementaron esta información con un webinar técnico en la página en Facebook del Cimat el viernes 5 de junio por la mañana.
La versión pre-print o pre-arbitraje de esta investigación remarca que ha sido utilizada para la toma decisiones de salud pública por el gobierno federal en México. También explica que su aplicación específica fue para proyectar la demanda hospitalaria relacionada con el coronavirus en las áreas metropolitanas del país. Entre sus limitantes, el artículo establece que es imposible pronosticar la proporción de la población mexicana que entrará en contacto con el virus hacia el final de esta oleada de Covid-19, debido a que se desconoce la cantidad exacta de contagios asintomáticos.
Los modelos de datos y la revisión por pares
Al ocultar la metodología de sus modelos matemáticos, la Secretaría de Salud impidió durante al menos seis semanas la verificación de los procesos que determinan la estrategia gubernamental contra el coronavirus. Así lo señala el epidemiólogo Andreu Comas en su columna “Modelando la pandemia”, publicada el 30 de mayo en Reforma: “Contar con varios modelos y no con uno solo durante una epidemia es de vital importancia… Hoy por hoy seguimos sin conocer a metodología del Modelo AMA… lo que dificulta un diálogo enriquecedor en la comunidad científica. También impide saber bien a bien con qué bases se están tomando decisiones de política pública”.
Para otro sector de la comunidad científica, las críticas eran un intento de golpear a las autoridades federales. “La vida política del país es muy delicada y la oposición está más preocupada por hacer un caso político de la pandemia que un problema de emergencia nacional”, dice el doctor Octavio Miramontes. Aunque su propio estudio, Entendamos el Covid-19 en México, sitúa el pico de contagios más de un mes después del pronosticado por la Secretaría de Salud, confía plenamente en la competencia y decisiones del grupo de Conacyt. “Muchos individuos también de la propia UNAM se han dedicado a bombardear al gobierno, a decir que es mentiroso, a decir que produce cosas falsas y todo sin pruebas. Si divulgan (los ejercicios matemáticos), va a haber un ejército de gente que va a decir que está mal. Me parece que es mejor que se lo callen”.
Los números de la pandemia siguen subiendo. Especialistas de la UNAM llamaron a extender el confinamiento voluntario durante al menos dos semanas más. El mismo día que inició el regreso escalonado a la nueva normalidad, México cruzó oficialmente el umbral de las 10 mil muertes por coronavirus. Por el futuro previsible, los modelos de datos (con todas sus incertidumbres y retos) seguirán determinando la estrategia contra el coronavirus.
“Hay una expresión muy famosa: todos los modelos se equivocan”, dice Esteban Hernández-Vargas, infectólogo matemático que actualmente trabaja en el Instituto de Matemáticas de la UNAM-Juriquilla. Coincide con académicos como Rojas y Gomeu, que apuntan a la necesidad de contrastar los resultados oficiales con los de otros modelos matemáticos. “Lo que deberíamos entender todos, no nada más López-Gatell, es que los modelos son posibilidades. Nadie tiene la verdad absoluta de todo esto. Tal vez juntando las diferentes verdades puedan tomarse mejores decisiones”.